 码恋
码恋
ALL YOUR SMILES, ALL MY LIFE.
ConcurrentHashMap锁的前世今生

我们知道,HashMap 是线程不安全的,为了使用线程安全的 HashMap,一种方法是使用 Collections 中的 synchronizedMap 方法。另一种方法是使用使用 ConcurrentHashMap。
一、Collections.synchronizedMap(Map map)锁的实现方式。
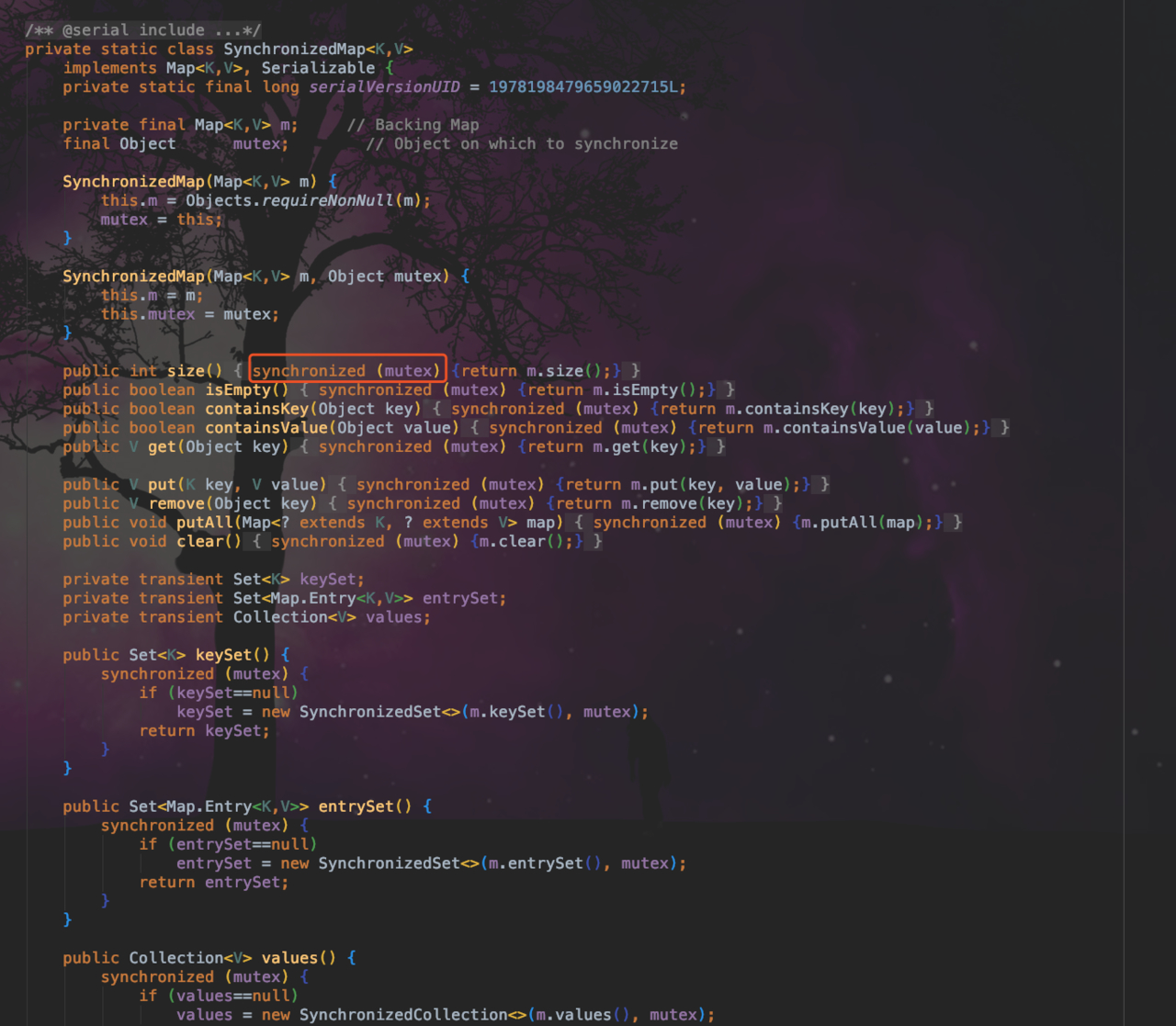
这里做一下延伸,我们简单看一下这个方法的源码,不出所料这个方法是重写了 HashMap 的方法,并且为这个 map 对象加了 synchronized 锁。如下图:
二、ConcurrentHashMap 锁的实现方式
在 Java 5 之后,JDK 引入了 java.util.concurrent 并发包 ,其中最常用的就是 ConcurrentHashMap 了, 它的原理是引用了内部的 Segment ( ReentrantLock ) 分段锁,保证在操作不同段 map 的时候, 可以并发执行, 操作同段 map 的时候,进行锁的竞争和等待。从而达到线程安全, 且效率大于 synchronized。
但是在Java8之后,JDK又弃用了分段锁的策略,重新使用synchronized来实现线程安全。
三、分段锁(java8之前)
我们先来看一下分段锁如何实现的。
- 数据结构
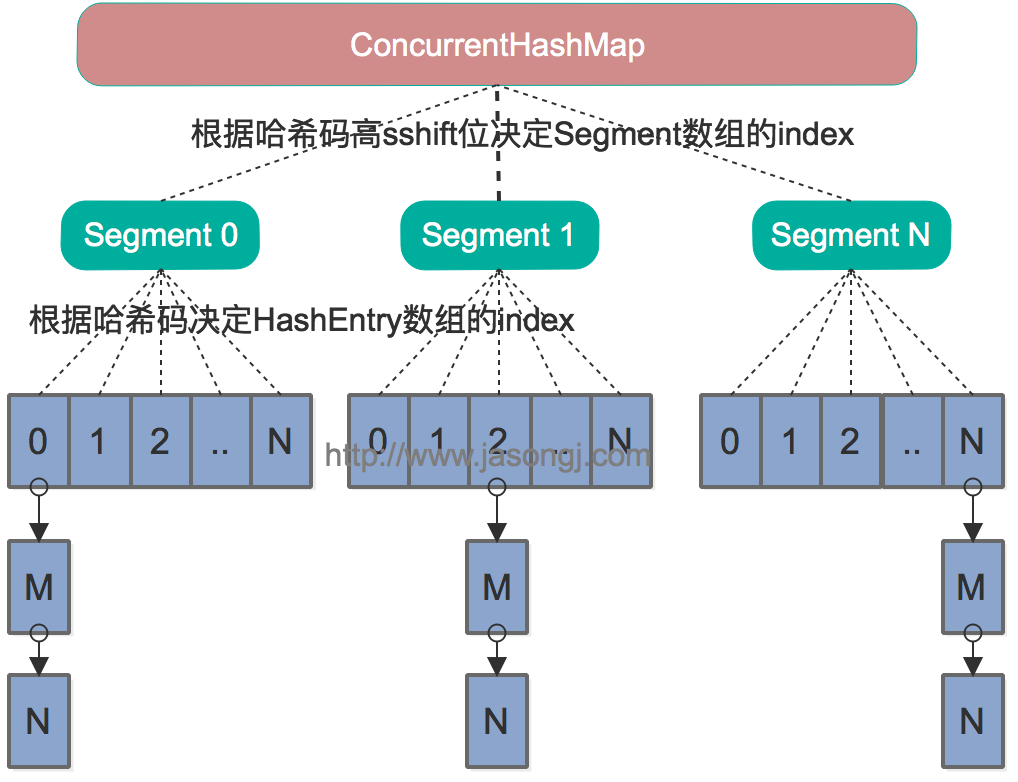
ConcurrentHashMap的底层数据结构和HashMap一样,仍然是数组和链表。不同点在于,ConcurrentHashMap的外层不是一个大数组,而是一个Segment数组,每个Segment包含一个和HashMap数据结构差不多的链表数组。如下图所示:
- 寻址方式
在读写某个Key时,先取该Key的哈希值。并将哈希值的高N位对Segment个数取模从而得到该Key应该属于哪个Segment,接着如同操作HashMap一样操作这个Segment。为了保证不同的值均匀分布到不同的Segment,需要通过如下方法计算哈希值。
private int hash(Object k) {
int h = hashSeed;
if ((0 != h) && (k instanceof String)) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
同样为了提高取模运算效率,通过如下计算,ssize即为大于concurrencyLevel的最小的2的N次方,同时segmentMask为2^N-1。这一点跟上文中计算数组长度的方法一致。对于某一个Key的哈希值,只需要向右移segmentShift位以取高sshift位,再与segmentMask取与操作即可得到它在Segment数组上的索引。
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
- 同步方式
Segment继承自ReentrantLock,所以我们可以很方便的对每一个Segment上锁。
对于读操作,获取Key所在的Segment时,需要保证可见性(请参考如何保证多线程条件下的可见性)。具体实现上可以使用volatile关键字,也可使用锁。但使用锁开销太大,而使用volatile时每次写操作都会让所有CPU内缓存无效,也有一定开销。ConcurrentHashMap使用如下方法保证可见性,取得最新的Segment。
Segment<K,V> s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)
获取Segment中的HashEntry时也使用了类似方法
HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE)
对于写操作,并不要求同时获取所有Segment的锁,因为那样相当于锁住了整个Map。它会先获取该Key-Value对所在的Segment的锁,获取成功后就可以像操作一个普通的HashMap一样操作该Segment,并保证该Segment的安全性。
同时由于其它Segment的锁并未被获取,因此理论上可支持concurrencyLevel(等于Segment的个数)个线程安全的并发读写。
获取锁时,并不直接使用lock来获取,因为该方法获取锁失败时会挂起(参考可重入锁)。事实上,它使用了自旋锁,如果tryLock获取锁失败,说明锁被其它线程占用,此时通过循环再次以tryLock的方式申请锁。如果在循环过程中该Key所对应的链表头被修改,则重置retry次数。如果retry次数超过一定值,则使用lock方法申请锁。
这里使用自旋锁是因为自旋锁的效率比较高,但是它消耗CPU资源比较多,因此在自旋次数超过阈值时切换为互斥锁。
- size操作
put、remove和get操作只需要关心一个Segment,而size操作需要遍历所有的Segment才能算出整个Map的大小。一个简单的方案是,先锁住所有Sgment,计算完后再解锁。但这样做,在做size操作时,不仅无法对Map进行写操作,同时也无法进行读操作,不利于对Map的并行操作。
为更好支持并发操作,ConcurrentHashMap会在不上锁的前提逐个Segment计算3次size,如果某相邻两次计算获取的所有Segment的更新次数(每个Segment都与HashMap一样通过modCount跟踪自己的修改次数,Segment每修改一次其modCount加一)相等,说明这两次计算过程中无更新操作,则这两次计算出的总size相等,可直接作为最终结果返回。如果这三次计算过程中Map有更新,则对所有Segment加锁重新计算Size。该计算方法代码如下
public int size() {
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
四、基于CAS的ConcurrentHashMap
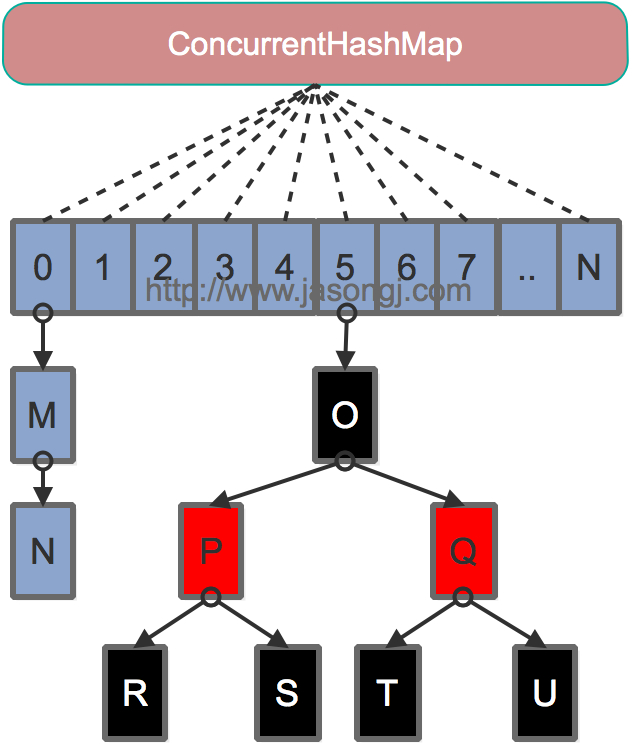
Java 7为实现并行访问,引入了Segment这一结构,实现了分段锁,理论上最大并发度与Segment个数相等。Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))。其数据结构如下图所示:
- 寻址方式
Java 8的ConcurrentHashMap同样是通过Key的哈希值与数组长度取模确定该Key在数组中的索引。同样为了避免不太好的Key的hashCode设计,它通过如下方法计算得到Key的最终哈希值。不同的是,Java 8的ConcurrentHashMap作者认为引入红黑树后,即使哈希冲突比较严重,寻址效率也足够高,所以作者并未在哈希值的计算上做过多设计,只是将Key的hashCode值与其高16位作异或并保证最高位为0(从而保证最终结果为正整数)。
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
- 同步方式
对于put操作,如果Key对应的数组元素为null,则通过CAS操作将其设置为当前值。如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作。如果该put操作使得当前链表长度超过一定阈值,则将该链表转换为树,从而提高寻址效率。
对于读操作,由于数组被volatile关键字修饰,因此不用担心数组的可见性问题。同时每个元素是一个Node实例(Java 7中每个元素是一个HashEntry),它的Key值和hash值都由final修饰,不可变更,无须关心它们被修改后的可见性问题。而其Value及对下一个元素的引用由volatile修饰,可见性也有保障。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
对于Key对应的数组元素的可见性,由Unsafe的getObjectVolatile方法保证。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
- size操作
put方法和remove方法都会通过addCount方法维护Map的size。size方法通过sumCount获取由addCount方法维护的Map的size。
下面,我们结合部分源码来看一下:
- put操作
首先通过 hash 找到对应链表过后, 查看是否是第一个object, 如果是, 直接用cas原则插入,无需加锁。
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable(); // 这里在整个map第一次操作时,初始化hash桶, 也就是一个table
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果是第一个object, 则直接cas放入, 不用锁
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break;
}
然后, 如果不是链表第一个object, 则直接用链表第一个object加锁,这里加的锁是synchronized,虽然效率不如 ReentrantLock, 但节约了空间,这里会一直用第一个object为锁, 直到重新计算map大小, 比如扩容或者操作了第一个object为止。
synchronized (f) {// 这里的f即为第一个链表的object
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}else if (f instanceof TreeBin) { // 太长会用红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
部分转自>>>here
