 码恋
码恋
ALL YOUR SMILES, ALL MY LIFE.
sharding的基本思想和基本切分策略

1. Sharding基本思想
Sharding,即分片、分区。分片的基本思想就和他字面的意思一样,就是把一个一个库根据一定规则(可能是业务模块,或者其他)切分为若干个库,分别存放数据,这样来讲,面对海量的数据,就可以把一个数据库的压力分散给其他不同的库,可以说一定程度上解决了数据库单库的性能瓶颈问题。当然,分片不只是在库的层面上,也可以延伸到单表的分片。
除此之外呢,切分也分为垂直切分和水平切分。根据一定的业务场景,可以选择不同的切分方式。如果是因为表的数量多而导致数据量大单库出现性能瓶颈时,可以选择垂直切分的方式,即可以根据业务模块,分为多个库,每个库中包含同一模块的表。如果是因为单表的数据量大而出现性能瓶颈,可以选择水平切分的方式,可以把表的数据按照一定的规则(常用的id散列)分别存储在不同的库表上。
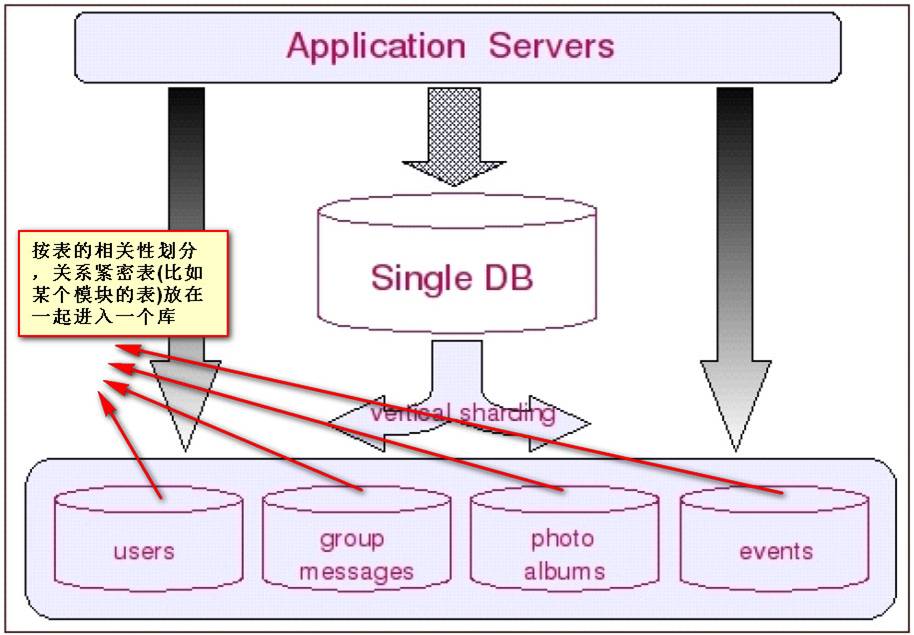
如果是业务模块之间有很清晰的界限,选择垂直切分就会更加简单清晰明了,对现有应用的影响也可以降到很小。非常适合在业务量达到一定程度,数据量大,而当初设计的数据架构不足以满足当前的业务需求。比如一个系统,设计之初,可能用户量没有那么多,用户模块,各业务模块全都放在一个数据库中。而随着用户数量、业务数据的增长,可以抽象出不同模块,将不同的表分别放在不同的库中,如下图:
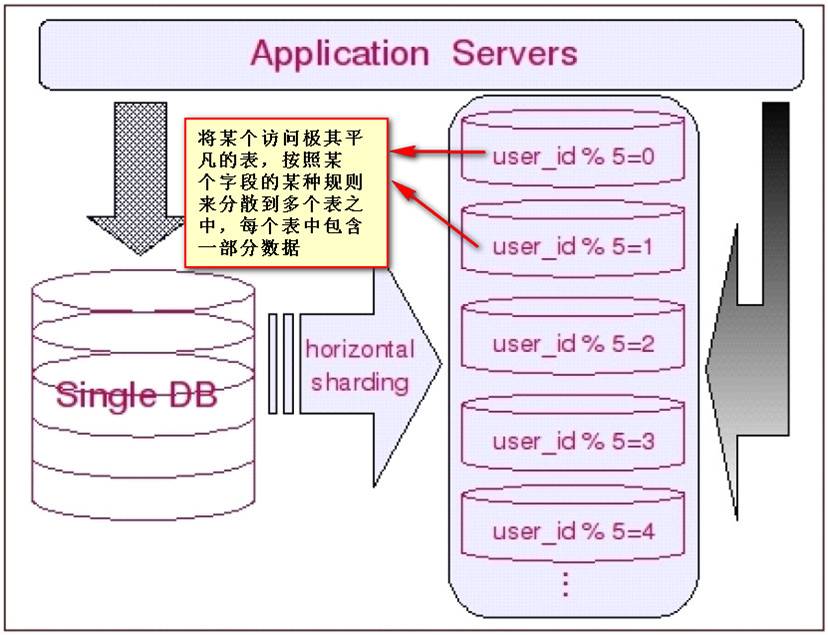
像上面说的,如果我有一张工单表,单表的数据量就有几千万甚至更多,并且还按照一定的数量增长,这个时候就要考虑分表进行水平切分。常用的可以按照主键进行散列算法切分,这样,生成的表随着分片数量可能会有这样,比如table_01,table_02...如下图,选择分片数量为5,按照user_id除以5取模的方式进行切分:
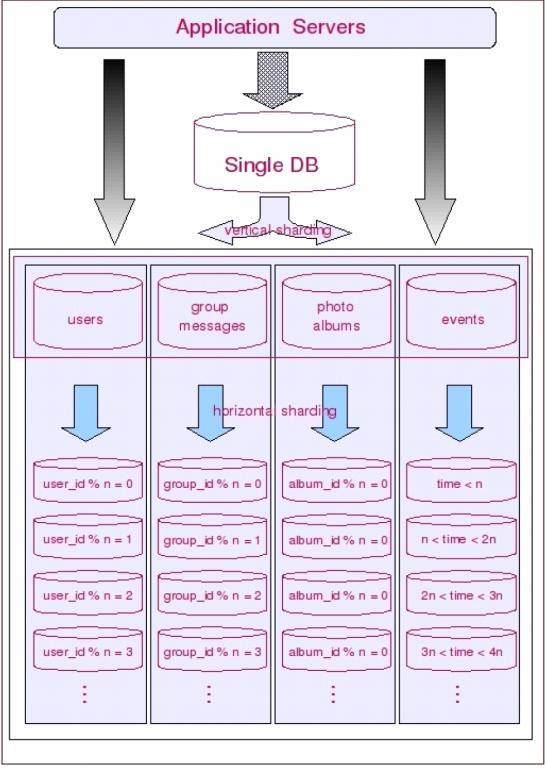
当然,面对现实中复杂的业务,可以两者共用。水平切分是把同一表的数据分散到多个表中,而垂直切分是按照不同的表来分到不同的库。我们可以这样想,同一个库中有多张表,不可能说总会有一张表把其他各个表都串联起来,经常会出现,一个库中的多个表并不是和其他表具有强耦合关系的。所以来讲,通常操作是对一个应用的表先进行垂直切分,再对大表进行水平切分。如下图:
2. 切分策略
如上所述,切实基本的切分策略已经很清楚了。套路就是先按照垂直切分,再按照水平切分。可以这样说,垂直切分的第一步,就是为了给水平分表做了铺垫。垂直切分时要考虑个表之间的关系,就是把一类的表放在一起,这样,不同类的表之间耦合低,各类的表数据操作隔离,可以尽量避免出现类似于分布式事务这样的难题。当然,总会有一些表,我们说,这类的表是各个类表共享的,可以集合具体的业务场景来做分析。比如,对于只读的字典表,可以在各个模块(也就是我们说的所谓的类)中都有一份...在此基础上,面对数据量大的表,再进行表层级的sharding。
当同时进行垂直和水平切分时,切分策略会发生一些微妙的变化。比如:在只考虑垂直切分的时候,被划分到一起的表之间可以保持任意的关联关系,因此你可以按“功能模块”划分表格,但是一旦引入水平切分之后,表间关联关系就会受到很大的制约,通常只能允许一个主表(以该表ID进行散列的表)和其多个次表之间保留关联关系,也就是说:当同时进行垂直和水平切分时,在垂直方向上的切分将不再以“功能模块”进行划分,而是需要更加细粒度的垂直切分,而这个粒度与领域驱动设计中的“聚合”概念不谋而合,甚至可以说是完全一致,每个shard的主表正是一个聚合中的聚合根!这样切分下来你会发现数据库分被切分地过于分散了(shard的数量会比较多,但是shard里的表却不多),为了避免管理过多的数据源,充分利用每一个数据库服务器的资源,可以考虑将业务上相近,并且具有相近数据增长速率(主表数据量在同一数量级上)的两个或多个shard放到同一个数据源里,每个shard依然是独立的,它们有各自的主表,并使用各自主表ID进行散列,不同的只是它们的散列取模(即节点数量)必需是一致的。
具体的拆分策略,我会在下一篇中做具体说明。
